
n8n实战:自动化生成AI日报并发布
n8n 在 Agentic AI 生态内已被广泛视为一款「低代码 × AI 编排」的核心框架,它让开发者与非开发者都能用拖拽的方式,将传统服务(数据库 / HTTP API)与各类大模型、向量检索无缝衔接,快速产出可落地的自动化场景。
本文将讲解如何利用 n8n 打造一条“AI 新闻采编与发布”流水线——它能在后台定时抓取多家科技媒体新闻,通过 OpenDataSky 大模型生成结构化中文日报并进行发布。整个过程无需手写后端代码,只需在 n8n 画布上完成节点配置。
什么是 n8n?
n8n(pronounced n-eight-n,“nodes & numbers” 的缩写)是一款开源的工作流自动化与集成平台。它提供:
- 可视化 DAG 设计器:每个节点代表一次 API 调用、脚本执行或 AI 推理。
- 内置 400+ 官方 / 社区节点:涵盖数据库、消息、云服务以及 LangChain AI 组件。
- 条件分支、错误重试、凭证集中管理与版本控制。
- 支持 JavaScript / TypeScript 片段,兼顾「无代码」与「可定制」。
简而言之,n8n 就是一条可以自由拼装的“数据 + AI 装配线”。
本教程要实现什么?
目标:一键生成「昨日 24h 内的 AI 行业要闻」并自动发布。流程示意如下:
定时触发器:
- 每 4 小时抓取 RSS → 抛入 “采集管道”
- 每天 09:00 启动 “日报生成管道”
采集管道(数据层)
- 读取 RSS → 标准化 JSON → 计算 MD5 去重
- Embedding → 向量 + metadata 写入 pgvector
摘要管道(语义层 / 内容层)
- 将关键词 Embedding → 相似度检索 top-K chunk
- LLM Prompt:排序、翻译、Markdown 排版
- 选择发布平台,调用接口发布
最终效果:无需人工干预,即可得到一份排版完整、中文易读的 AI 日报。
技术栈一览
- n8n 1.93.0 + @n8n/n8n-nodes-langchain
- PostgreSQL 14 + pgvector 0.6(也可使用 n8n 内置向量存储)
- OpenDataSky API(兼容 OpenAI SDK)获取 API Key
如何使用 n8n ?
1. 使用网页版: n8n 官方提供的云服务,访问 n8n 官网 登录使用。(需要付费订阅使用,新用户14天免费试用)
2. 本地部署: 部署在本地运行,根据 官方文档 部署即可。
同样,n8n 支持部署在 DataSky AI 云盒 中使用,本文为 DataSky AI 云盒部署实践所得。
编排工作流
整个自动化工作主要分为两个独立的流程分别实现:
- 获取新闻资讯的流程
- 生成相关话题日报的流程
下面将分别拆解这两个工作流程进行分析。
首先登录进 n8n 界面,点击“Create Workflow”创建空白工作流。
获取新闻资讯
配置定时触发器
点击“Add first step...”,选择“On a schedule”创建定时触发器。
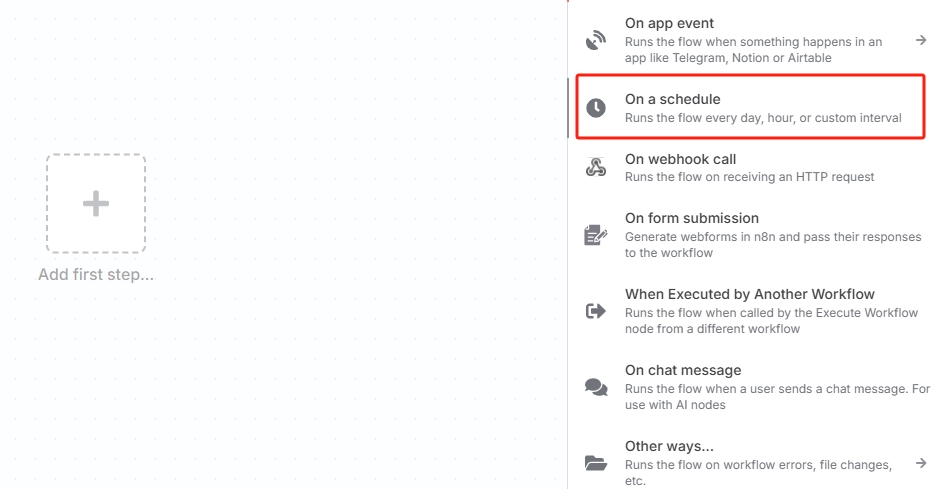
也可以根据实际情况选择其他触发器,工作流需要自动化运行则必须要以触发器为首个节点
注意: 由于 n8n 默认使用的美国时区,为保证定时器正常按预期触发,则需要修改时区。
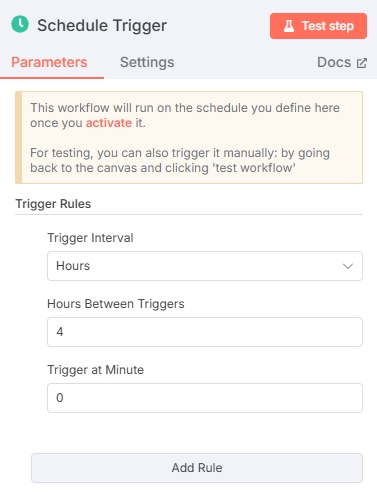
点开“On a schedule”节点自定义配置时间,根据需要的触发频率配置即可。这里我们选择每4小时触发一次。
其他触发器
当然也可以直接使用RSS触发器“RSS Feed Trigger”,RSS触发器也支持配置触发时间频率。
由于RSS触发器不便后续添加多项RSS新闻源,遂建议使用“On a schedule”触发器先配置时间,后续节点配置RSS新闻源。(若只有一条新闻源则可以使用“RSS Feed Trigger”)
设置RSS新闻源地址
在定时器后添加“Edit Fields”节点,节点中定义好RSS地址数组。可以按照如下配置:
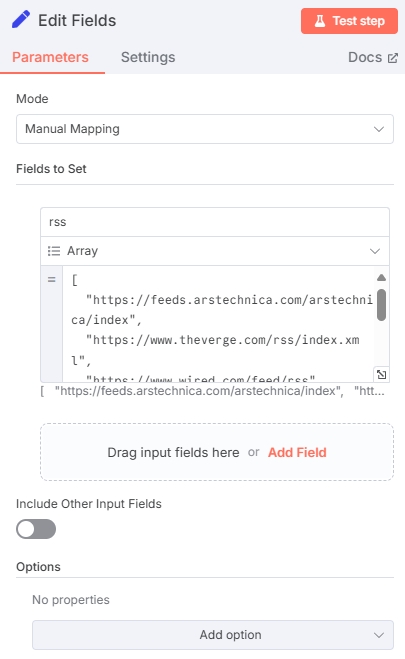
类型一定要选择“Array”数组,以下是输入的模板
[
"https://feeds.arstechnica.com/arstechnica/index",
"https://www.theverge.com/rss/index.xml",
"...其他RSS源地址"
]点击“Test Step”测试这个节点,可以看到输出应该是这样:

RSS地址可以在各新闻媒体平台上找到
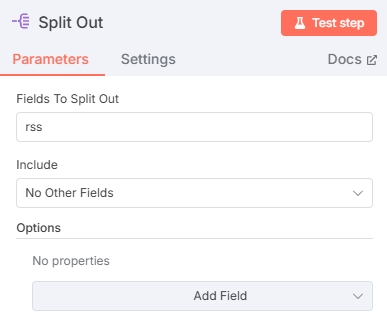
拆分数组
需要将上一个节点的数组拆分为不同的items才能给后续RSS阅读节点使用:
测试输出如下:
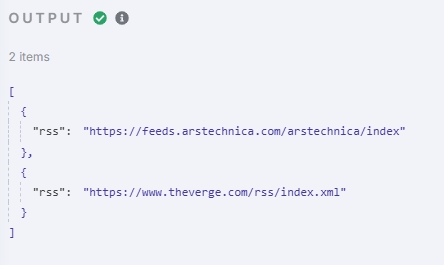
可以看到经过这个节点数组已经被成功拆分,items 数量为 2
阅读 RSS 新闻源
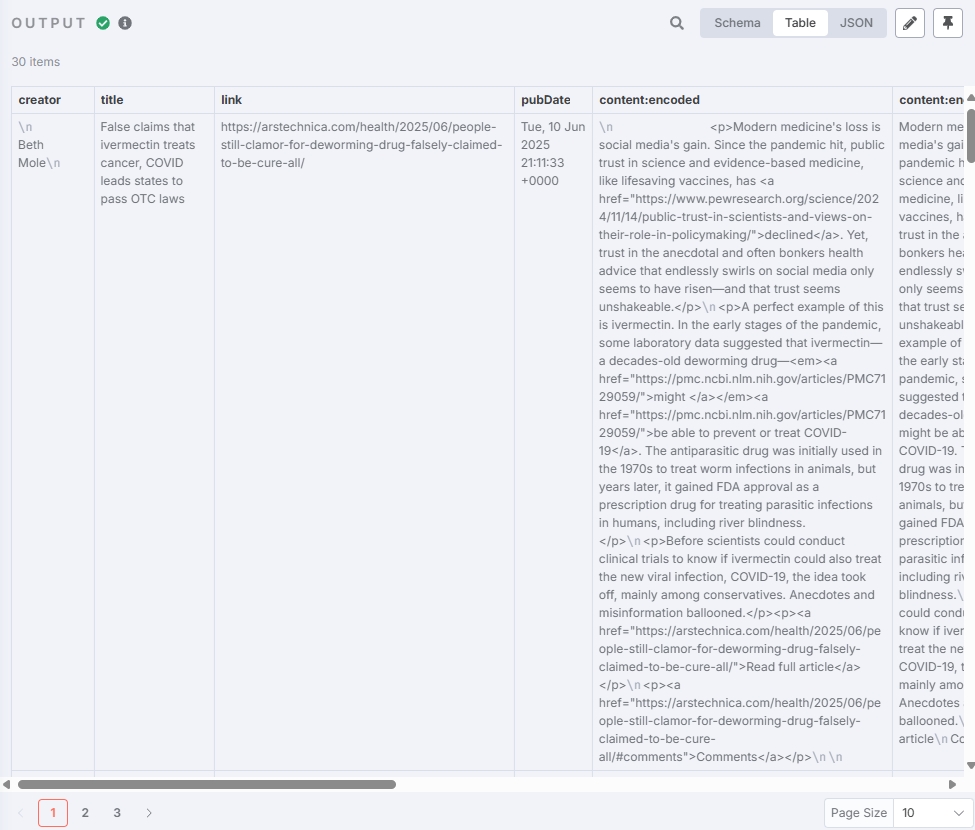
添加 RSS Read 节点提取新闻内容,URL一栏输入上一个节点输出的rss变量 $json.rss ,RSS Read 节点将会输出每一个URL中的新闻:
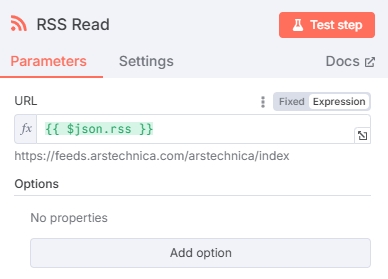
测试得到新闻内容:
提取有效字段
再次添加“Edit Fields”节点,用于提取后续所需的有效字段
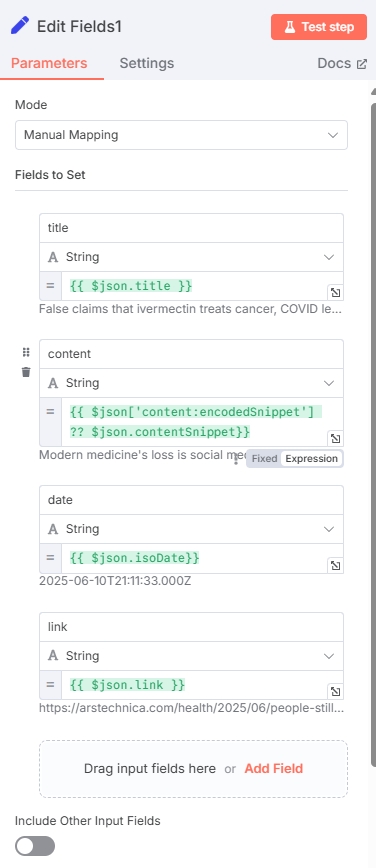
| 字段名 | 字段类型 | 值(变量) |
|---|---|---|
| title | String | $json.title |
| content | String | $json['content:encodedSnippet'] ?? $json.contentSnippet |
| date | String | $json.isoDate |
| link | String | $json.link |
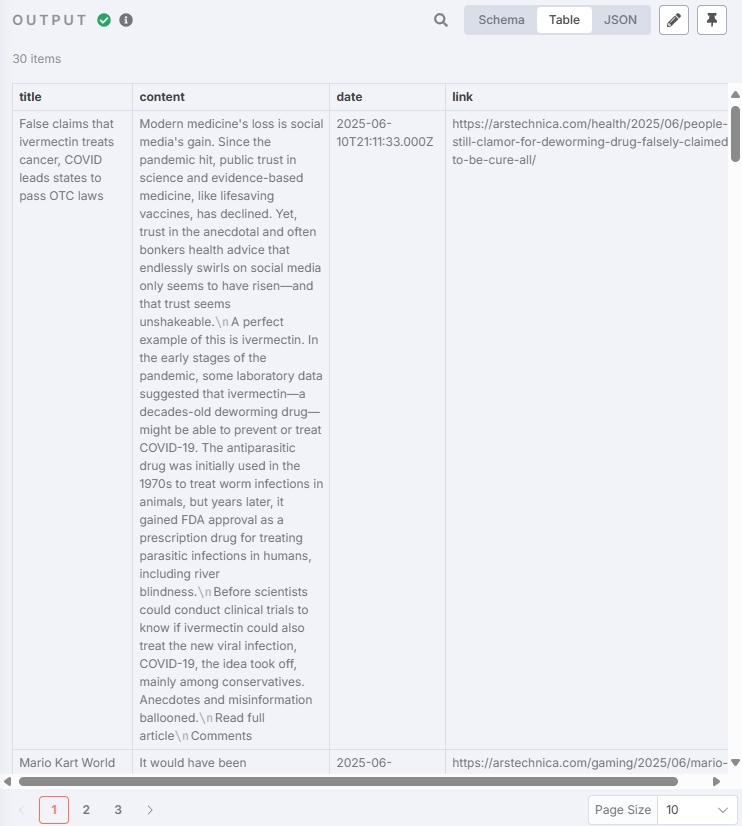
测试输出结果为:
生成 Hash 值(可选)
本节点目的是对获取的文章标题生成标识符,方便后续对文章进行去重
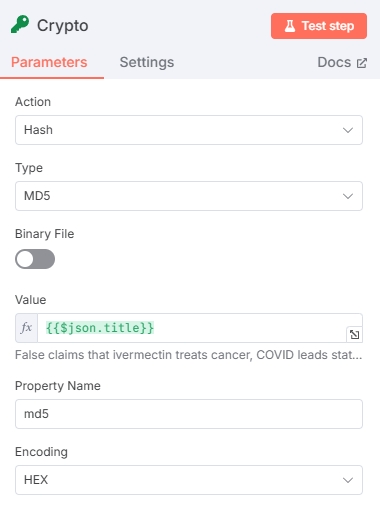
测试结果:
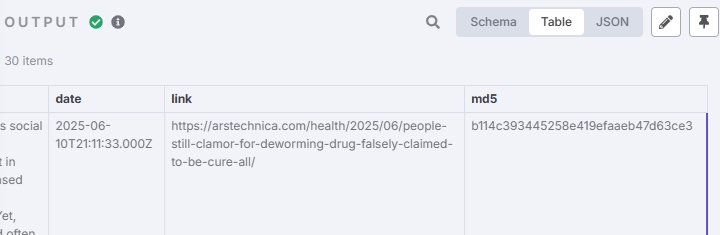
将新闻作为矢量存储
矢量存储能够在大量新闻的情况下,提供语义进行检索,从而获得更加符合话题的资讯文章。(若不需要这么高的精准度,可以直接存入 SQL 后续再根据简单的关键词检索数据库即可)
添加 Vector Store 节点
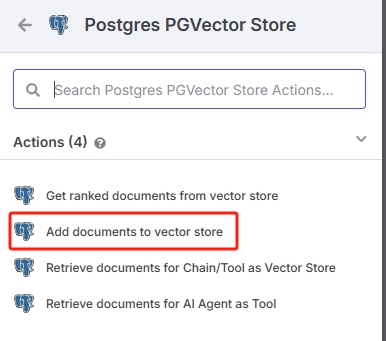
除数据库节点外,矢量存储还需要另外3个节点配合:嵌入模型节点、数据加载器、文本分割器

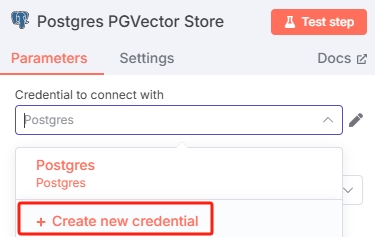
配置数据库凭证
点开 Postgres PGVector Store 节点在“Credential to connect with”一栏添加数据库凭证
按照自己搭建的数据库配置即可。但是要注意:PostgreSQL 需要安装 pgvector 扩展才可以使用向量存储,不知道怎么安装可以去查找一下相关教程。
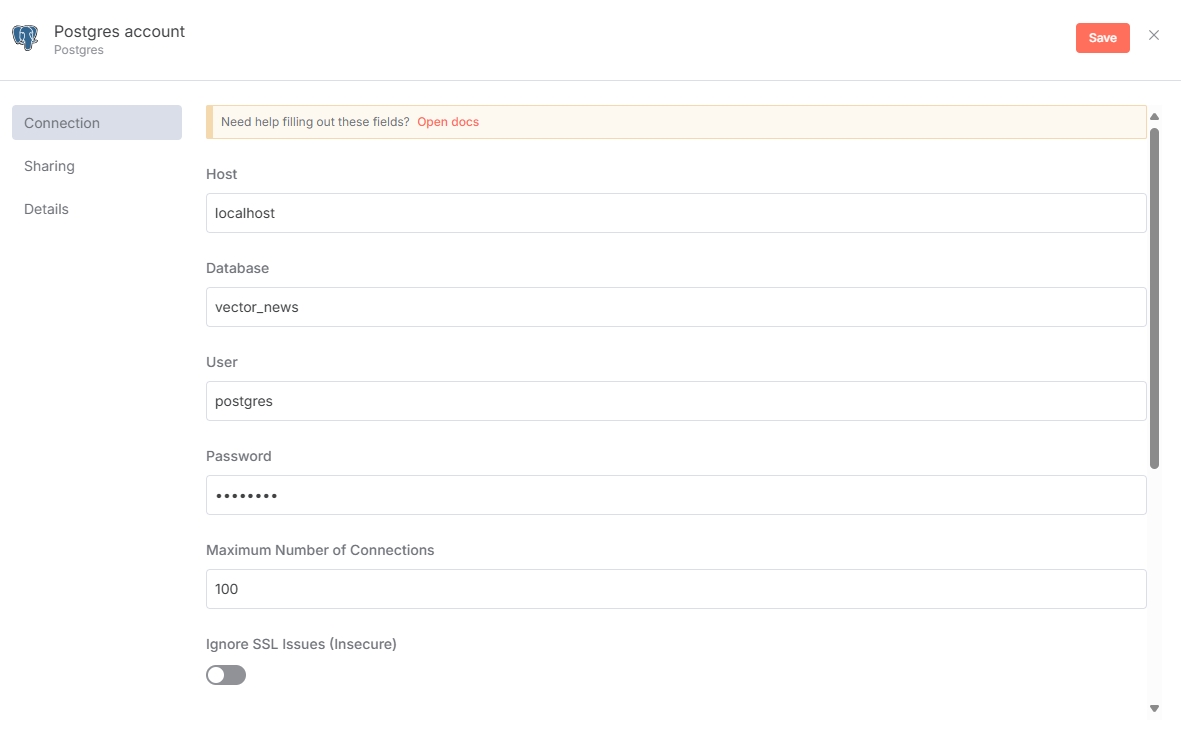
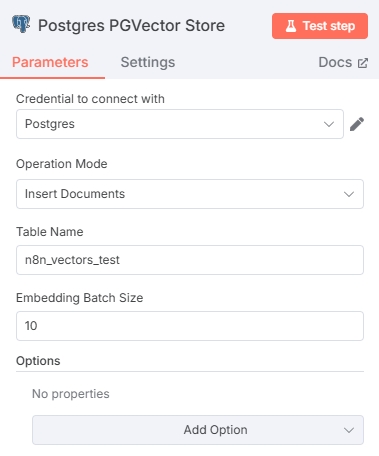
数据库凭证添加好后,配置 Postgres PGVector Store 节点,Table name 不要与数据库中的表名冲突即可,Embedding Batch Size 参数跟使用的嵌入模型有关,可以酌情选择。
配置嵌入模型
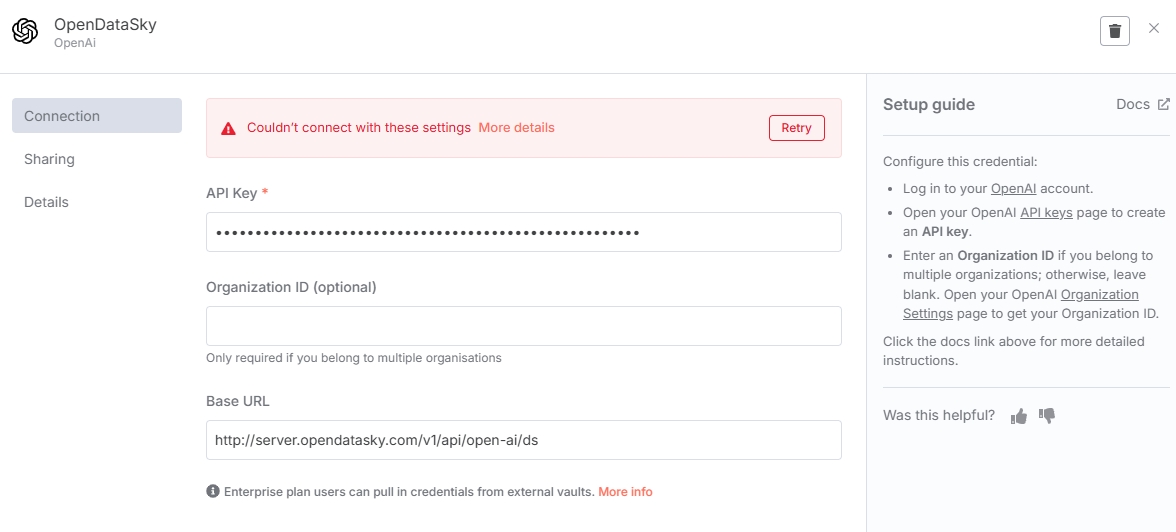
在 Embeddings 节点中添加嵌入模型资源,首先需要添加 API 接口凭证。这里可以填入 OpenDataSky 的 API,Base URL 输入 http://server.opendatasky.com/v1/api/open-ai/ds ,API Key 前往平台获取。
注意
保存 API 凭证的时候,n8n 会调用 /modellist 接口来验证连通性。由于 OpenDataSky 暂未开放 /modellist 接口,所以点击保存时会出现错误提示,忽略即可。(不会影响后续模型的调用)
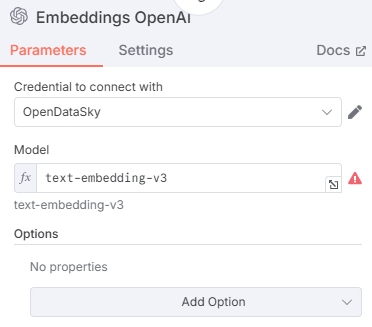
输入嵌入模型 ID,这里选择了通义千问系列的嵌入模型 text-embedding-v3,也可以选择其他模型。支持的模型见模型列表
配置数据加载器
数据加载器负责加工上面节点输出的新闻数据,数据类型选择 JSON。
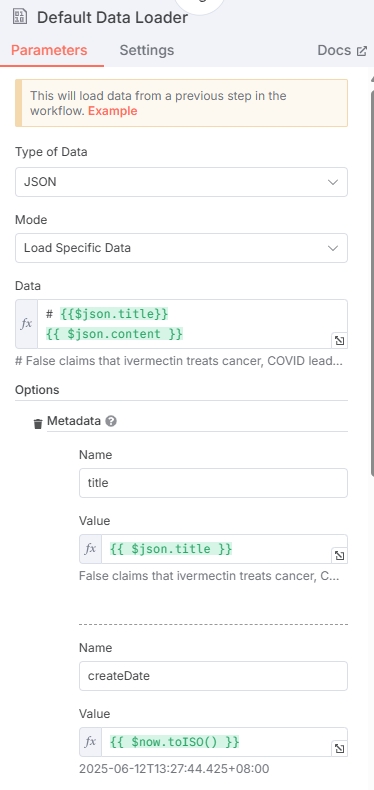
这里输出的数据会进入向量化的过程,所以选择性地提供需要向量化的数据(比如文章标题与正文),Mode 选择 Load Specific Data,Data 中合并新闻标题+正文,复制下面的变量即可。
# {{$json.title}}
{{ $json.content }}除此之外,还需要额外配置 Metadata 数据,Metadata 将会以 jsonb 类型存储在 PostgreSQL 中,配置标题、hash、链接、时间,防止这些数据丢失,也可以加入一些其他字段(如createDate)。
点击 “Add Option” 配置 Metadata,可以按照例子填写
| Name | Value |
|---|---|
| title | $json.title |
| createDate | $now.toISO() |
| publishDate | $json.date |
| link | $json.link |
| title_hash | $json.md5 |
填写 Value 时输入框要选 “Expression” 表达式
在 metadata 中配置好 title_hash 后,可以在 PostgreSQL 中添加触发器,在写入数据库时将 title_hash 提取为单独的一列,方便后续查询。(也可以直接在 metadata 的 json 中查询,这样不需要触发器)
触发器示例:
CREATE OR REPLACE FUNCTION extract_title_hash()
RETURNS trigger AS $$
BEGIN
NEW.title_hash := NEW.metadata ->> 'title_hash';
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_extract_title_hash
BEFORE INSERT OR UPDATE ON n8n_vectors_test
FOR EACH ROW EXECUTE FUNCTION extract_title_hash();注意
使用该触发器需要保证数据库已经存在 title_hash 列,可以手动创建 title_hash 列,类型 text。
配置文本分割器
添加文本分割器节点时,建议选择 “Recursive Character Text Splitter” 类型,会将新闻分割完整的段落。
节点内设定一个合理的 Chunk Size 即可,不需要 Chunk 之间的数据重叠 Chunk Overlap 设置为 0。(Chunk Size 不宜设置得太高,会超出嵌入模型的 Max Tokens)
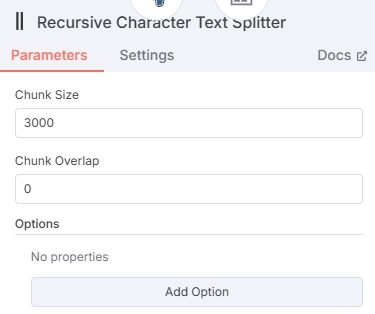
测试
根据以上步骤将矢量存储配置好后,在“Postgres PGVector Store”节点中点击“Test step”进行测试。
测试结果应当如下:
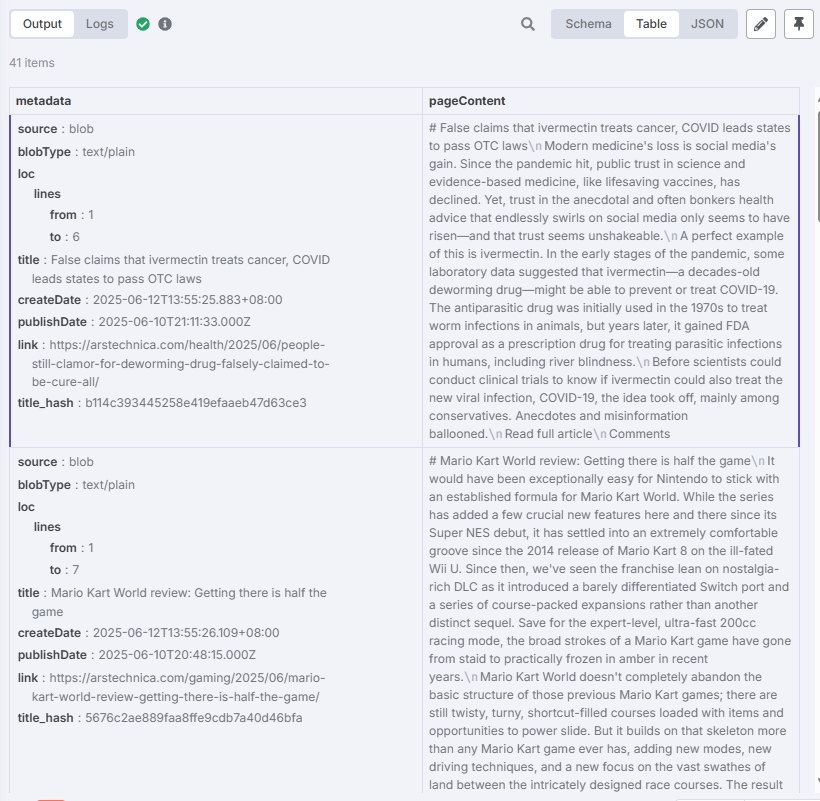
可以看到文章都已存入数据库。
当前的工作流节点应当如下:
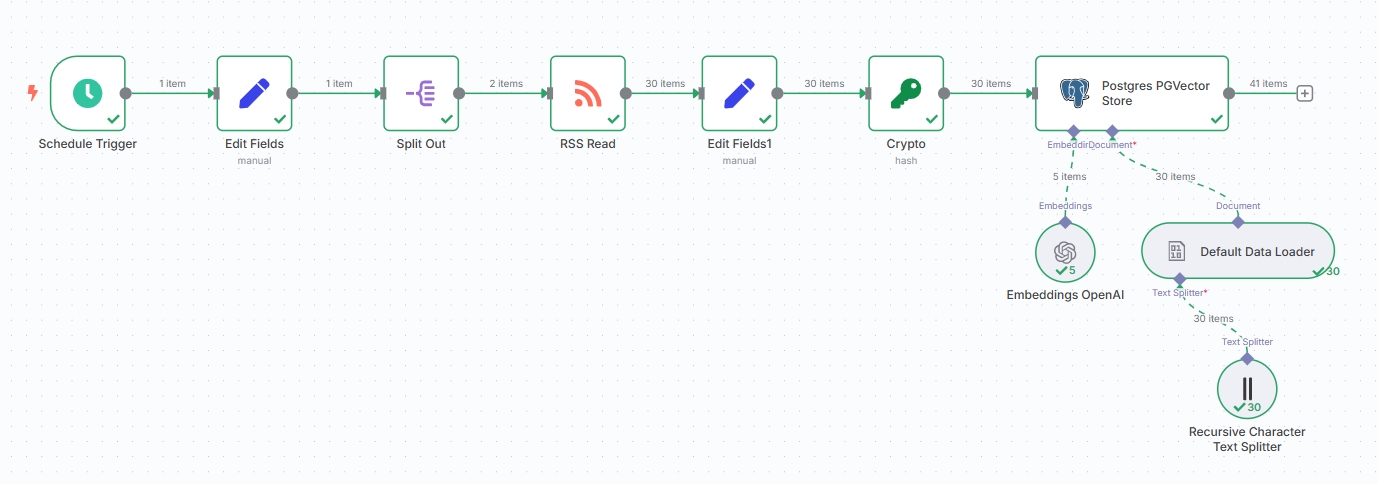
提示
当然,也可以把 Postgres PGVector Store 替换为 n8n 内置的向量存储 “Simple Vector Store”,但 Simple Vector Store 不适合持久化存储,且无法执行后续的去重工作,不推荐。
文章去重(可选)
由于在之前的节点中添加了生成 Hash 值的节点,所以可以利用生成出来的 Hash 值对重复文章进行筛选
去重需要使用两个节点来实现:“Postgres”和“Merge”分别用来查询和合并。同时需要先断开生成 Hash 值的节点与数据库存储的连接,后续由其他节点提供输出到数据库节点。
Postgres节点
由生成 Hash 值节点作为输出,添加新的节点。
选择 Postgres节点动作为 SQL 查询。注意不要和“Postgres PGVector Store”节点混淆,“Postgres PGVector Store”和“Postgres”不是一个类型。
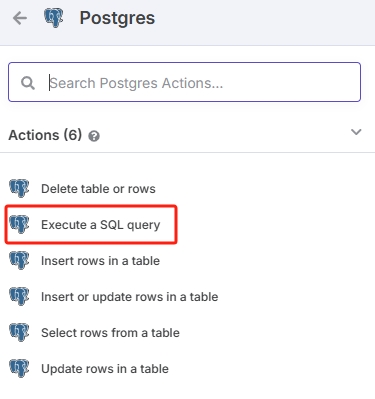
根据之前的流程,在此节点输入查询语句,查找有哪些重复的 Hash。
SELECT DISTINCT title_hash FROM n8n_vectors_test WHERE title_hash IN ('{{ $json.md5 }}');若未根据上面的步骤创建 title_hash 触发器(数据库没有 title_hash 列,只有 metadata 的情况下),可以使用这个命令查重:
SELECT DISTINCT metadata->>'title_hash' AS title_hash
FROM n8n_vectors_test
WHERE metadata->>'title_hash' IN ('{{ $json.md5 }}');配置与测试结果如图:
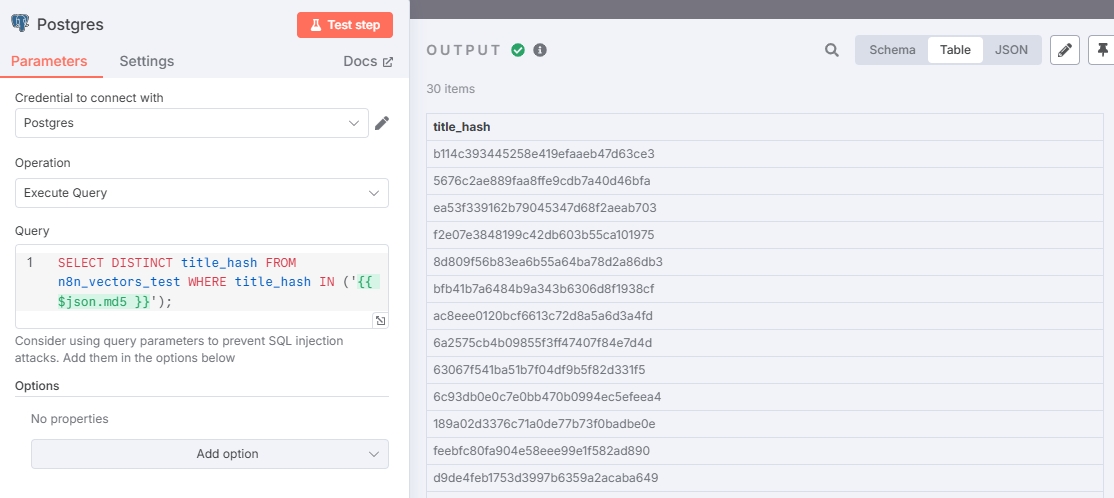
由于没有抓取新的数据所以测试中的所有 hash 值都是重复的。表明输出正确。
Merge节点
添加 Merge 节点,将生成 Hash 值和Postgres节点一同作为输入方。
如图,Postgres 节点连接 Input 1 ,生成 Hash 值节点连接 Input 2。

Merge 节点使用 SQL 查询筛选掉重复文章
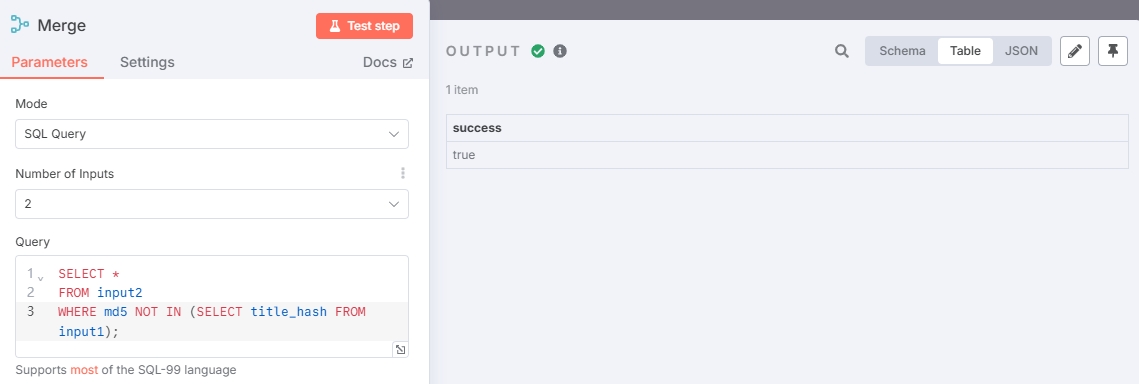
附上查询语句
SELECT *
FROM input2
WHERE md5 NOT IN (SELECT title_hash FROM input1);由于数据未更新,所有文章都是重复的,所以没有输出未重复的文章。此时可以添加其他 RSS 地址重新测试(或者等一段时间,让当前的 RSS 输出新的新闻)
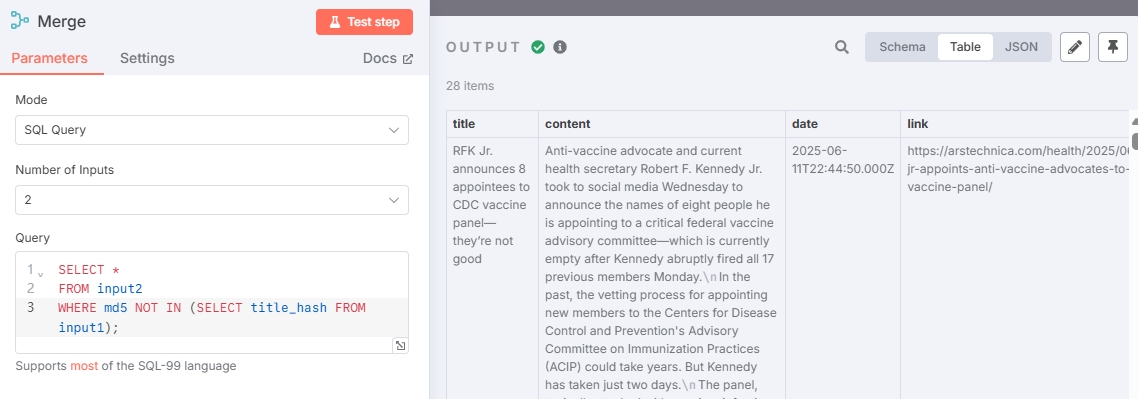
再将去重后的新闻接入“Postgres PGVector Store”节点完成整个新闻存储流程。
附上完整的获取新闻资讯流程:
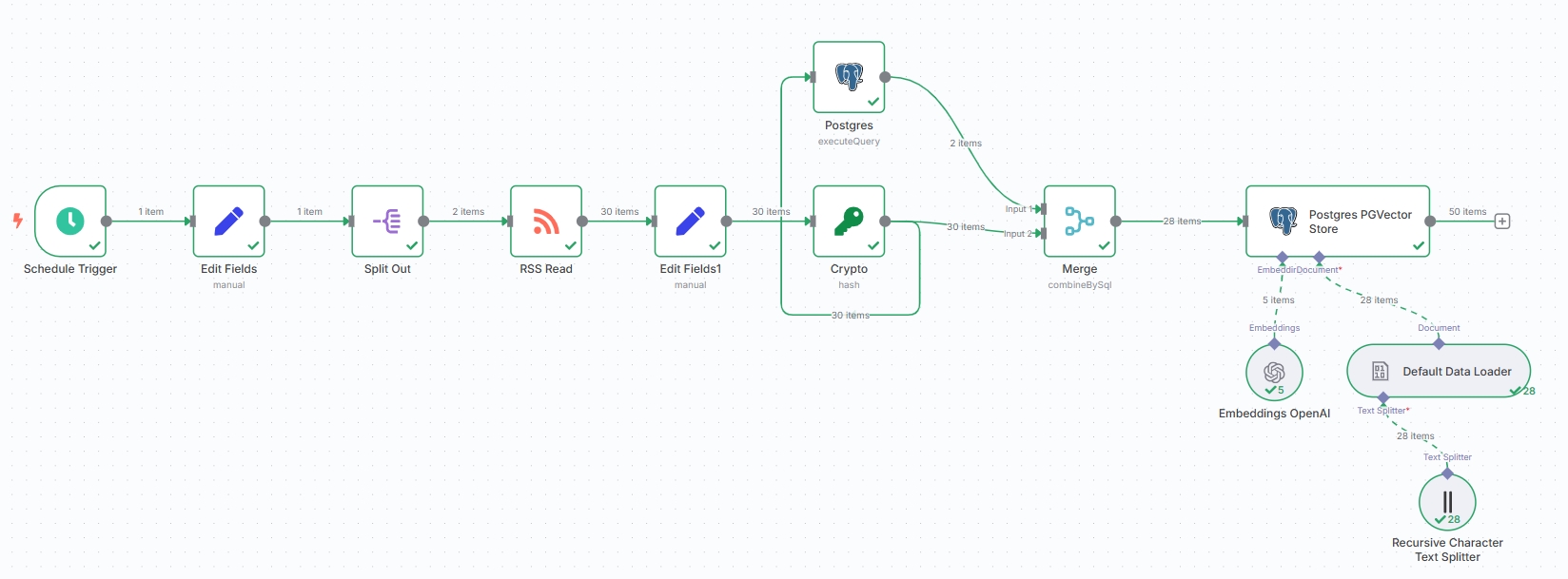
检索相关新闻并生成日报
配置定时触发器
由于是一个新的独立流程,所以需要从配置触发器开始。配置同获取新闻定时触发器相同,不再赘述。
添加向量检索节点
通过向量检索相关新闻,添加 Postgres PGVector Store 节点,Actions 选择 Get ranked documents from vector store。
![]()
选择在获取新闻资讯流程中的数据库与表,Prompt 根据需要检索的话题编写即可。Limit 输入一个合适的值,会限制文章的输出数量。需要开启“Include Metadata”选项
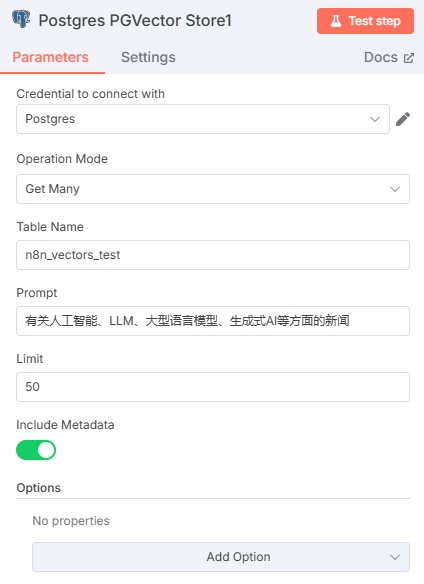
- 建议 Prompt 为完整的一句话,语义检索更准确。
若需要根据新闻时间进行过滤,建议在 PostgreSQL 中添加时间筛选的视图(View),在 Table Name 一栏填入视图名称,后续就会检索符合条件的新闻。
View 创建示例(只提供 publishDate 在24小时以内的新闻):
CREATE OR REPLACE VIEW articles_last_24h AS
SELECT *
FROM n8n_vectors_test
WHERE (metadata->>'publishDate')::timestamptz >= NOW() - INTERVAL '24 hours';此时 Postgres PGVector Store 节点的 Table Name 一栏填写 articles_last_24h 就会只检索24小时以内的新闻了。
添加 Embedding
将此节点的 Embedding 连接至之前配置的 “Embeddings OpenAI” 节点即可,在 将新闻作为矢量存储步骤中。也可以新建一个 “Embeddings OpenAI” 节点(注意:一定要与之前的 Embedding 节点使用相同的模型。)
测试结果如下:
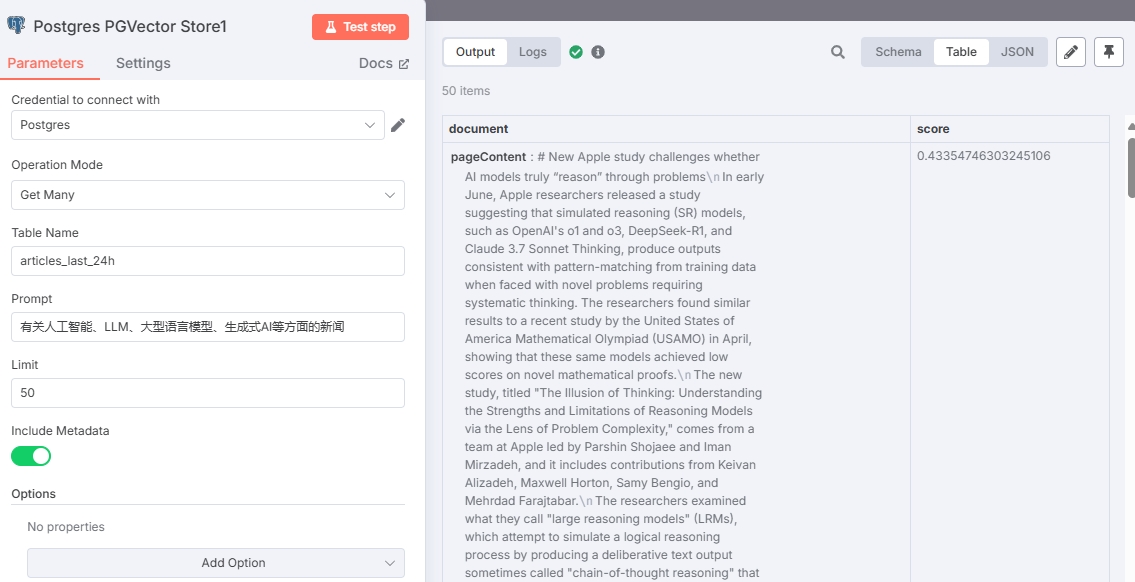
由于 n8n 的查询方式导致 score 值为欧氏距离(L2),所以 score 值越小相似度越高。
筛选相识度高的内容/Chunk
在上一个节点中,查询到的文章是最相近的 50 篇(由 Limit 决定),但在这 50 篇中可能存在相似度不高的文章。所以,需要一个节点用以筛选出达到相识度(score 值)的文章。
添加 Filter 节点,配置如图:
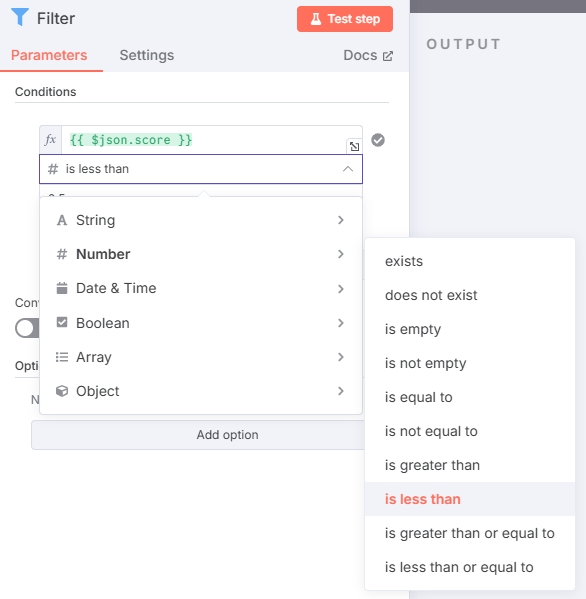
输入一个合适的值,筛除掉 score 高于该值的文章。(score值越高,相似度越低。示例中筛选值设置为 0.5 ,可根据实际测试调整)
本次测试结果:
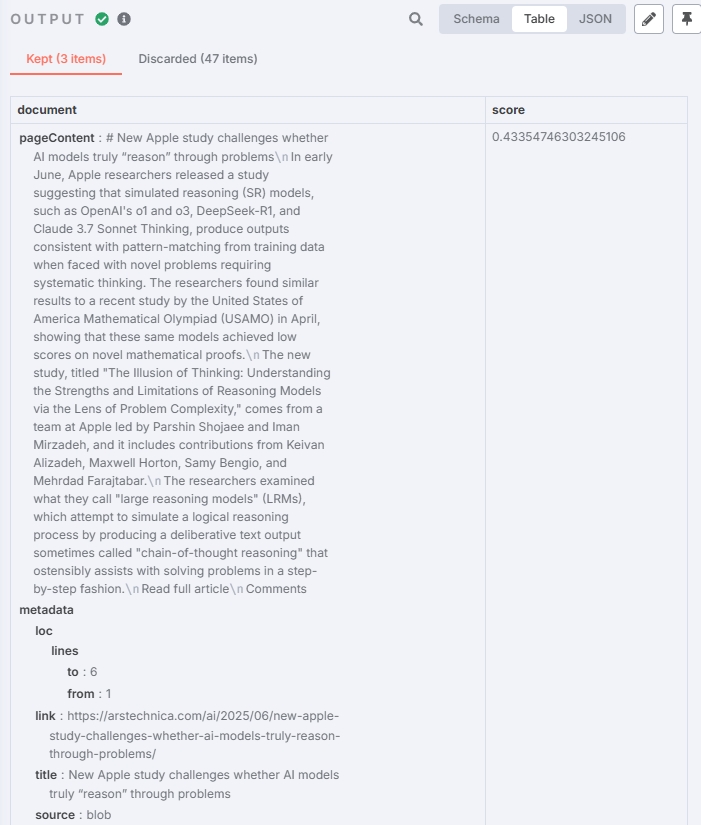
成功筛选出了相关的新闻的 Chunk,效果也符合预期。
提取 Chunk 中的 Hash 值(可选)
因为在上一个步骤中,筛选出来的数据为新闻的 Chunk,若是一篇长篇文章,则会被文本分割器分割成好几块 Chunk,将这些 Chunk 发送给大模型可能会造成文章的不完整。所以这里可以将匹配到的 Hash 值提取出来,再使用 Hash 值去拼接完整的文章。
这里选择 “Code” 节点,示例如下:
const unique = [...new Set(items.map(i => i.json.document.metadata.title_hash))];
return unique.map(hash => ({ json: { title_hash_unique: hash } }));输出结果:
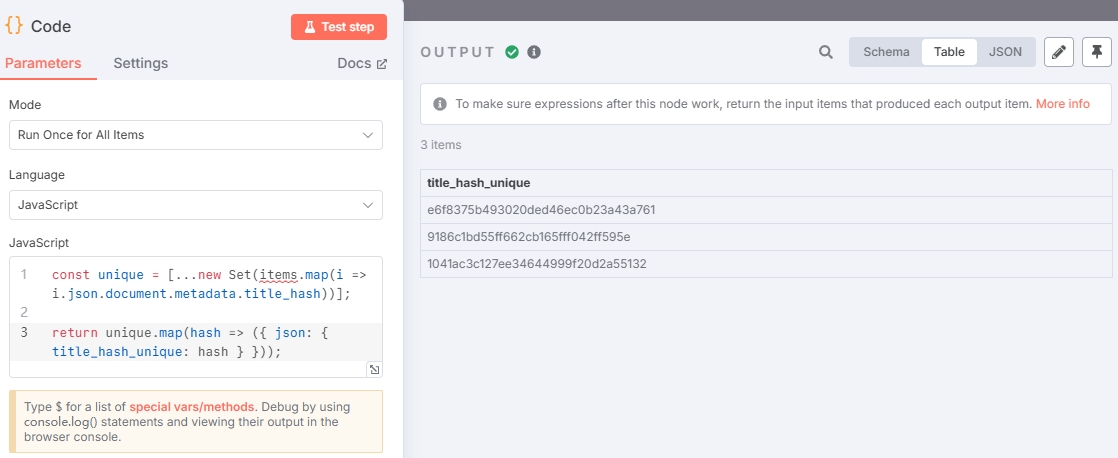
使用 Hash 拼接完整文章(可选)
添加 PostgreSQL 查询节点:
将上一个步骤输出的 Hash 用来查询数据库,同时对文章进行拼接,用一段 SQL 就可以实现:
WITH parts AS (
SELECT
title_hash,
text,
metadata ->> 'link' AS link,
metadata ->> 'title' AS title,
metadata ->> 'publishDate' AS publish_date,
(metadata #>> '{loc,lines,from}')::int AS line_from,
(metadata #>> '{loc,lines,to}')::int AS line_to
FROM n8n_vectors_test
WHERE title_hash IN ('{{ $json.title_hash_unique }}')
)
SELECT
title,
string_agg(text, ' ' ORDER BY line_from, line_to) AS body,
link,
publish_date
FROM parts
GROUP BY
title_hash,
link,
title,
publish_date
ORDER BY
title_hash,
publish_date;输出结果:
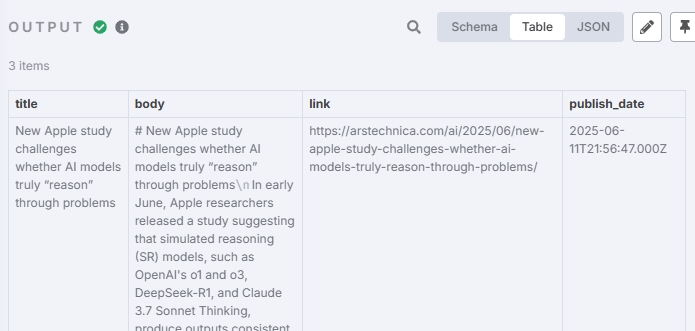
合并 items
若需要将所有文章一起发给大模型,则需要将上面步骤输出的 items 合并为一条。否则后面的大模型会根据 items 数量一个一个地进行请求。
这里还是使用 “Code” 节点,示例代码:
const arr = items.map(item => item.json); // 获取所有输出内容
return [
{
json: {
myArrayStr: JSON.stringify(arr), // 转为字符串
}
}
];输出结果:
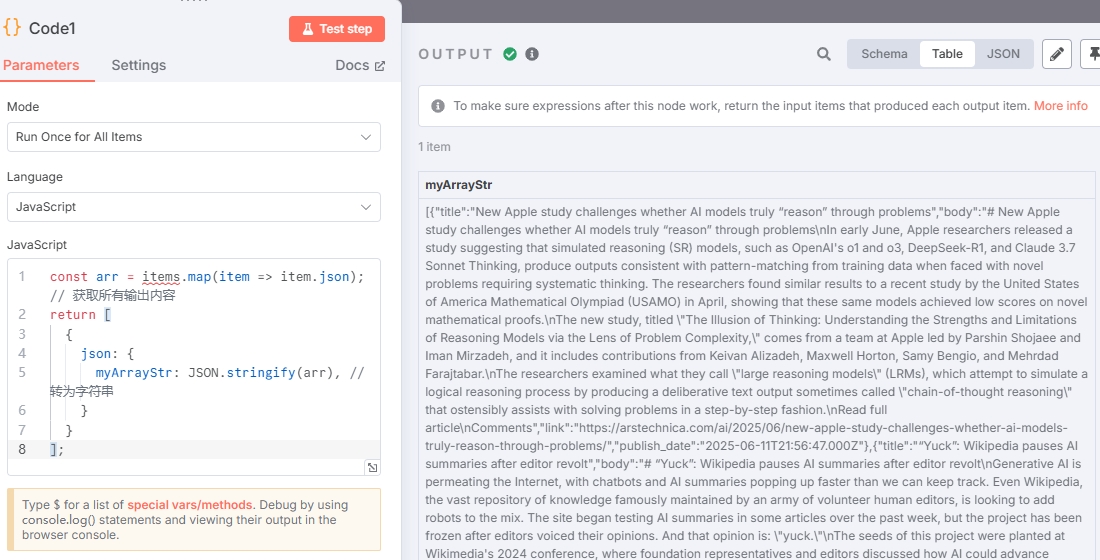
可以看到只有一个 item 了。
生成日报
到这一步就可以将新闻材料发送给大模型,让大模型进行总结了。
添加 AI Agent 节点,“Source for Prompt” 选择 “Define below” 自定义 Prompt。简单的 Prompt 示例:
你是一位专业的新闻编辑,请根据以下材料总结一篇 AI 相关的新闻资讯:
{{ $json.myArrayStr }}这里还需要添加大模型(Chat Model)才能使用,选择 “OpenAI Chat Model”,由于 OpenDataSky API 凭证已在之前配置嵌入模型时提供了,所以这里只需要输入 Model ID 就可以。
查看 OpenDataSky 支持的 Chat Model
使用 gpt-4.1-mini-2025-04-14 测试输出结果:

Prompt 可以根据需求进行优化,以达到符合预想的效果。
发送日报
之后的步骤就完全按照需求和喜好来制定了,比较通用的方法是:使用 HTTP Request 节点连接各种平台实现自动化发送,或使用 Send Email 发送邮件。也可以使用 n8n 内置的一些节点配置会更加简单。
以 QQ 邮箱为例,需要在 Send Email 节点添加 QQ 邮箱的凭证,User 就是你的邮箱地址,Host 输入邮箱官方提供的地址 smtp.qq.com,Password 则需要去 QQ 邮箱设置中生成授权码(QQ 邮箱的登录密码是不能用于第三方的),Port 和 SSL/TLS 使用默认的就行(465 和 开启 )。
简单指引:
网页QQ邮箱 -> 设置 -> 账号 -> POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务在此根据指引生成授权码即可。
可以看到 Email 成功保存。
在 “Send Email” 中 “From Email” 要和凭证中的 User 邮箱一致,“To Email” 填写需要发送到的邮箱地址即可(也可以发给自己)。
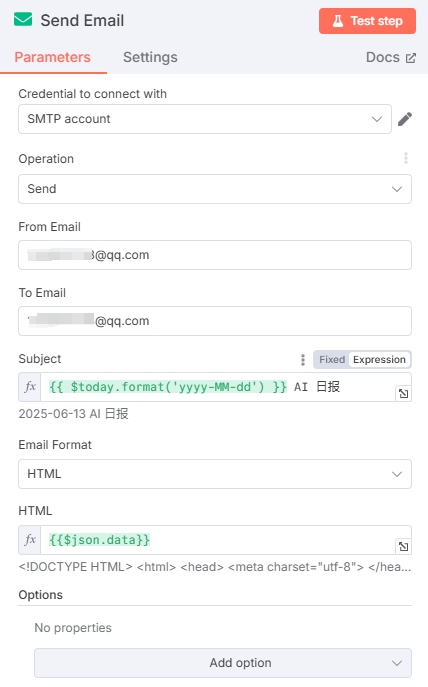
由于大模型输出的内容主要为 Markdown 格式,而邮箱不支持 Markdown,所以在生成日报和邮箱节点中添加了一个 Markdown 转 HTML 的节点。
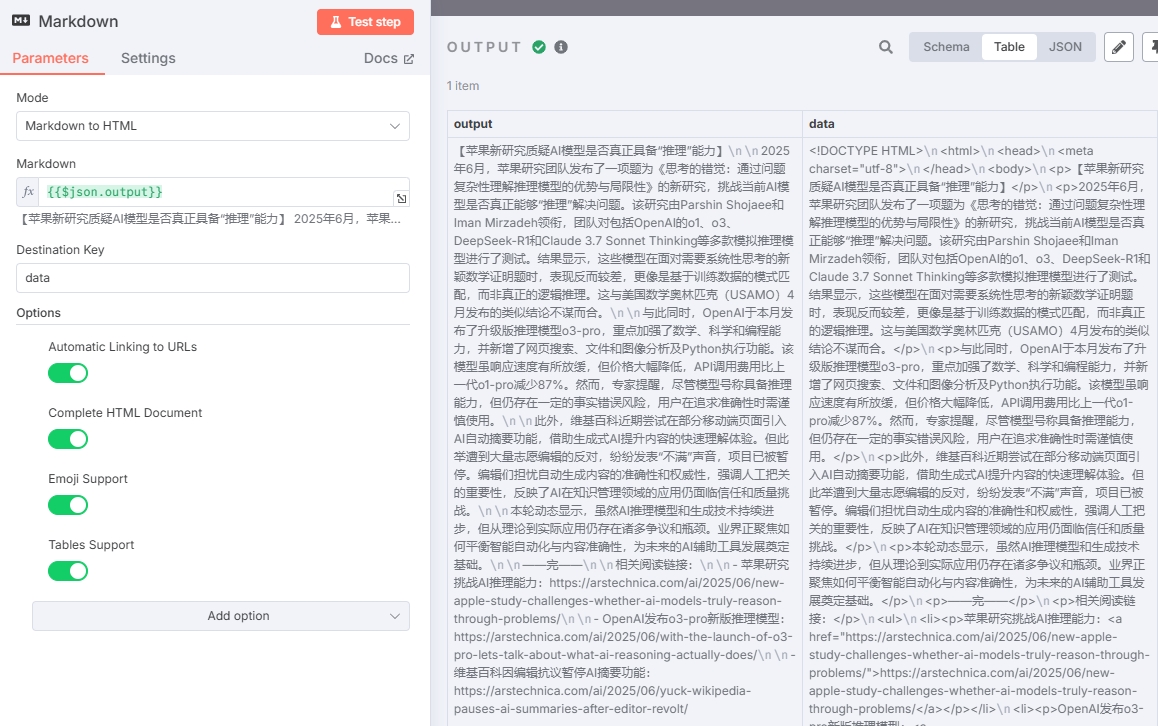
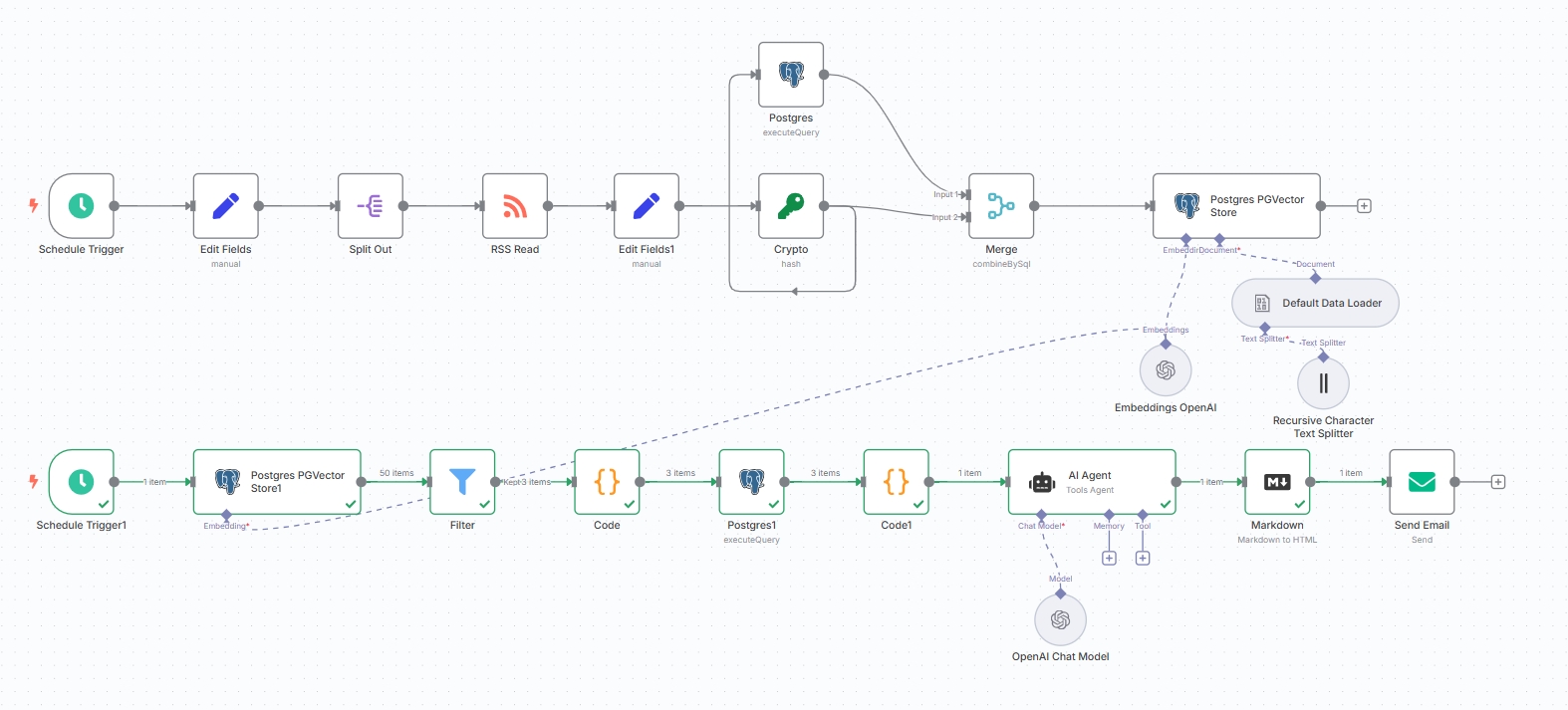
最后得到完整的工作流如图:
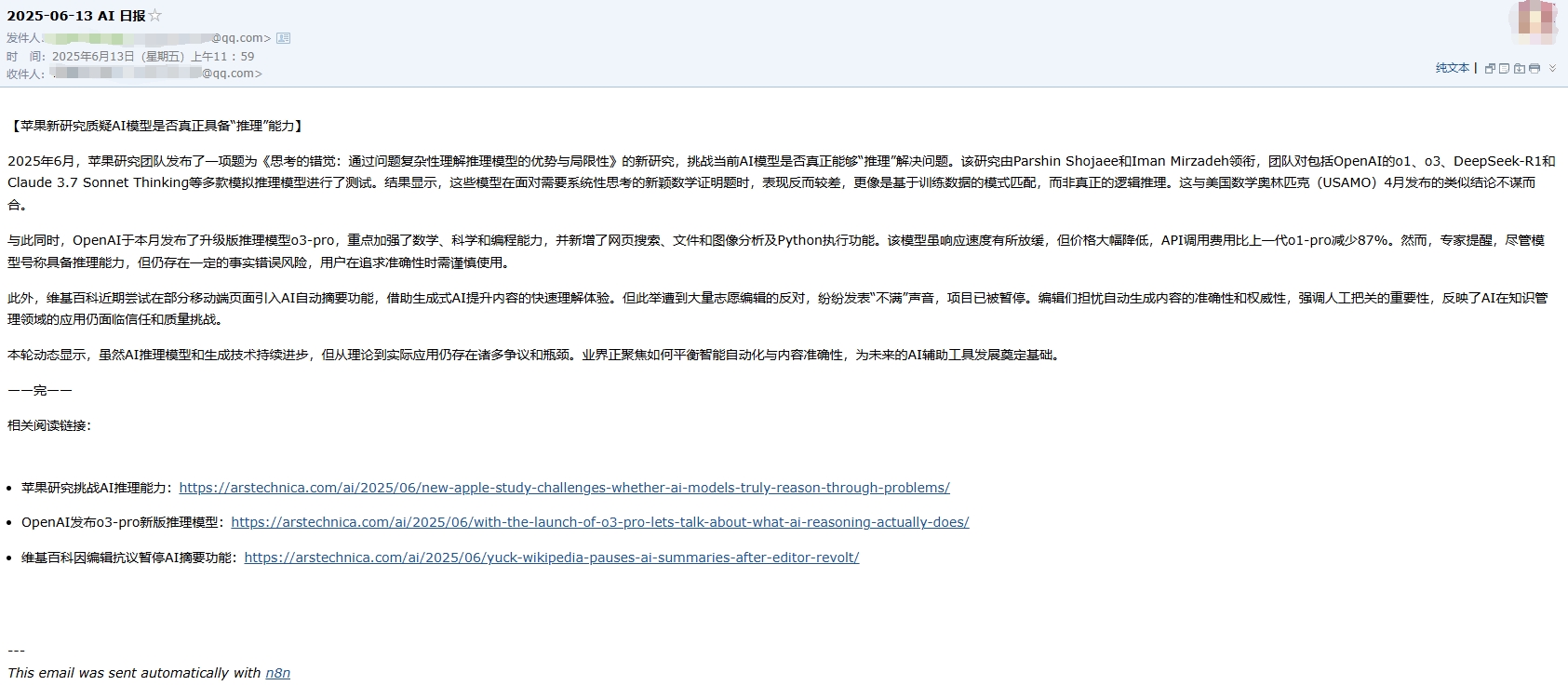
查看一下邮箱的邮件:
结语
通过本文的详细实践,我们成功构建了一套完整的AI日报自动化生成系统。这不仅仅是一个技术演示,更是展现了n8n在AI工作流编排中的强大潜力。
掌握n8n + AI的核心技能,这不仅是一个技术工具,更是连接传统业务与AI能力的桥梁。在AI原生应用的时代,这样的自动化能力将成为企业和个人的核心竞争力。
开始行动吧! 从复制本文的工作流开始,逐步定制属于你的AI自动化解决方案。记住,最好的学习方式就是在实践中不断迭代和优化。